"Kỳ lân" Zhipu AI phát triển mô hình giống GPT-4o tại Trung Quốc
Sơn Trần
10/09/2024
Chia sẻ
Mô hình trực quan mới nhất của kỳ lân AI Trung Quốc có thể đọc và hiểu nội dung cả video lẫn trang web…

Kỳ lân AI Trung Quốc, Zhipu AI, đang tăng tốc nhằm giành vị trí dẫn đầu cuộc đua trí tuệ nhân tạo đa phương thức. Hồi tháng 7, công ty chính thức ra mắt Zhipu Qingying, mô hình tạo video tương tự như Sora, theo Kr Asia.
Sora của OpenAI được giới chuyên gia đánh giá là công cụ AI tạo sinh cho ra những thước phim chất lượng tốt nhất hiện nay. Tuy nhiên, sau nhiều tháng ra mắt, Sora vẫn không thể truy cập, còn Qingying cung cấp tài khoản sử dụng miễn phí cho công chúng từ ngày đầu xuất hiện.
Một tháng sau, vào ngày 29 tháng 8, Zhipu trở thành tâm điểm tại Hội nghị Quốc tế Phát hiện và Khai thác Kiến thức (KDD) với việc ra mắt "Her", mô hình tương tự GPT-4o. Sản phẩm được công ty khẳng định là hướng tới người tiêu dùng Zhipu Qingyan bởi sở hữu chức năng "gọi video" mới có tích hợp AI, tiến gần hơn đến khả năng giao tiếp giống con người.
Ngoài ra, Qingyan cũng cập nhật xu hướng khá nhanh. Sau khi trò chơi Black Myth: Wukong nổi tiếng, mô hình nhanh chóng hiểu và có thể bàn luận với người dùng.
Bên cạnh cập nhật trên, Zhipu còn tung ra bộ mô hình đa phương thức mới, bao gồm mô hình trực quan GLM-4V-Plus (cả video và trang web) và mô hình chuyển văn bản thành hình ảnh CogView-3-Plus.
Mô hình ngôn ngữ cơ bản GLM cũng được nâng cấp lên GLM-4-Plus, có khả năng xử lý văn bản dài và giải quyết vấn đề toán học phức tạp một cách dễ dàng.
TRỢ LÝ GIÚP LÀM BÀI TẬP VỀ NHÀ, GIA SƯ VÀ CÔNG VIỆC BẾP
Trước đây, GPT-4o khiến người dùng trầm trồ với khả năng dự đoán cảm xúc. Nhưng Qingyan có cách tiếp cận đơn giản hơn. Khi bắt đầu sử dụng, mô hình nhắc nhở người dùng rằng, là một AI, chúng sẽ không thể hiện cảm xúc.
Điều đó cho thấy, tính năng gọi video của Qingyan có nhiều ứng dụng thực tế, phù hợp với chủ trương của Trung Quốc về học tập suốt đời.
Chẳng hạn, khi công cụ trở thành gia sư tiếng Anh cá nhân, người dùng có thể bật camera và học theo yêu cầu, mọi lúc, mọi nơi. Hay khi Qingyan là giáo viên toán, lời giảng của công cụ sánh ngang với gia sư ngoài đời thực, hỗ trợ rất nhiều cho bậc phụ huynh.
Tại nhà, Qingyan đóng vai trò là trợ lý cá nhân. Chúng có thể phân biệt túi cà phê và cung cấp thông tin ngắn gọn lịch sử thương hiệu. Mặc dù đôi khi có chút sai sót, như công cụ gợi ý cách bảo quản túi thay vì cà phê bên trong.
MÔ HÌNH TRỰC QUAN MỚI: TỪ HIỂU VIDEO ĐẾN DIỄN GIẢI MÃ
Tại KDD, Zhipu AI công bố bản cập nhật bao gồm thế hệ mới của mô hình ngôn ngữ cơ sở và đa phương thức nâng cao: GLM-4V-Plus và CogView-3-Plus.
Đáng chú ý, GLM-4-Plus được đào tạo bằng dữ liệu tổng hợp chất lượng cao, chứng minh dữ liệu do AI tạo ra cực kỳ hiệu quả trong việc đào tạo mô hình và giảm chi phí. Theo Zhipu AI, khả năng hiểu ngôn ngữ của GLM-4-Plus ngang bằng với một số đối thủ như GPT-4o và Llama3.1-405B.
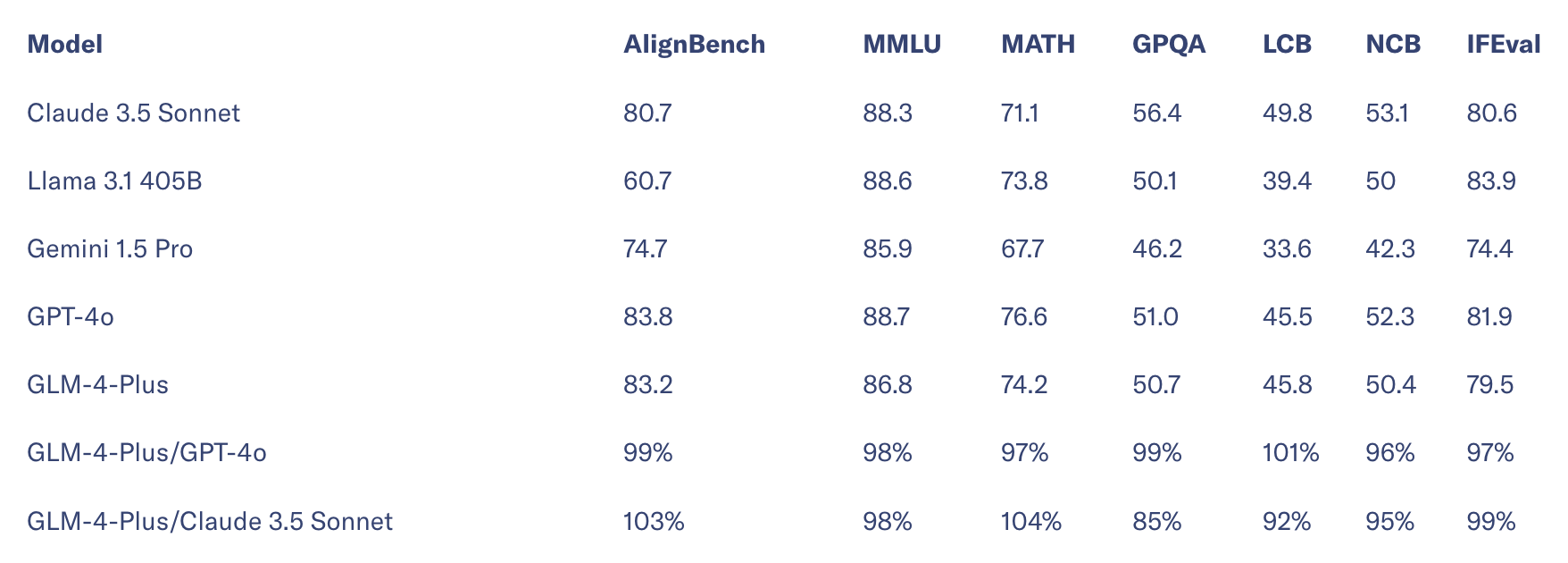
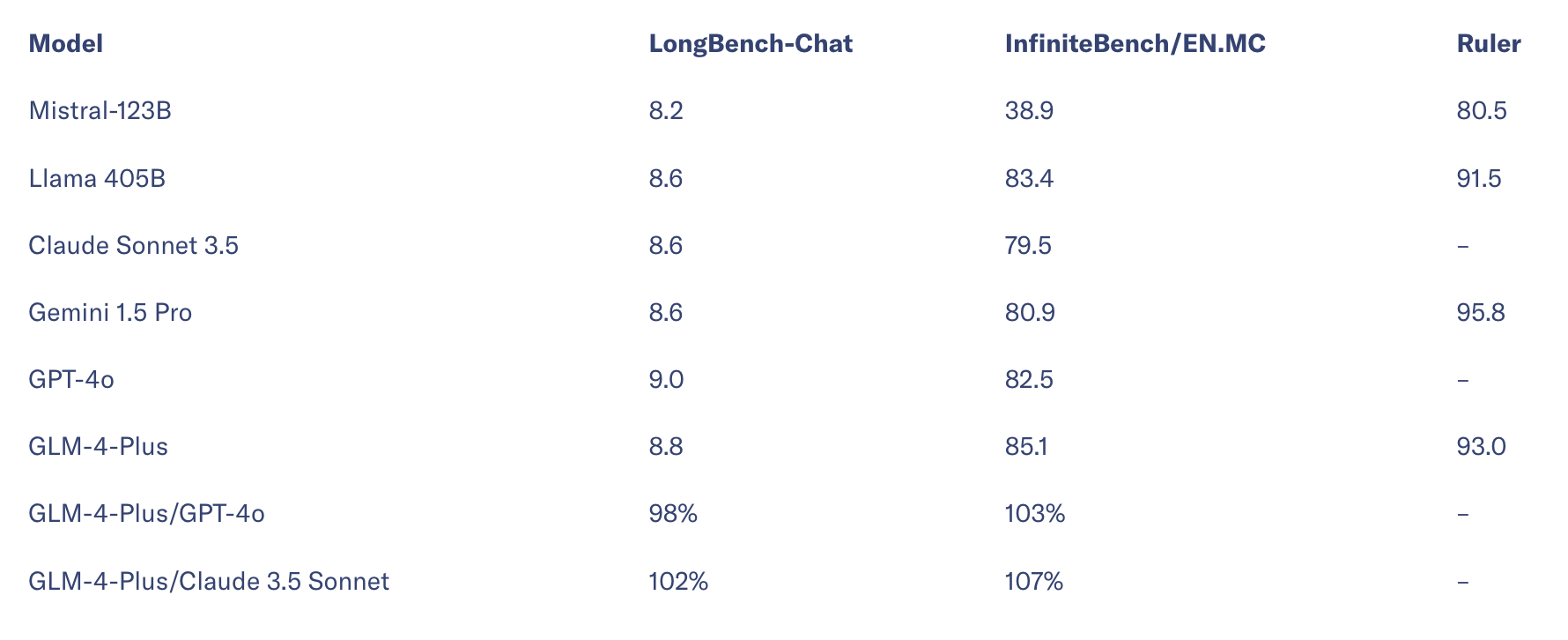
Về khả năng xử lý văn bản dài, GLM-4-Plus hoạt động ngang với GPT-4o và Claude 3.5 Sonnet. Trên bộ thử nghiệm InfiniteBench, được tạo ra bởi nhóm của Liu Zhiyuan tại Đại học Thanh Hoa, GLM-4-Plus thậm chí còn vượt trội hơn một chút so với các mô hình hàng đầu hiện nay.
Hơn nữa, bằng cách tối ưu hóa chính sách gần đúng (PPO) - phương pháp tăng khả năng ra quyết định trong nhiều nhiệm vụ phức tạp - GLM-4-Plus có thể suy luận dữ liệu phù hợp hơn với sở thích con người.
Chi phí xử lý cho 1 triệu mã thông báo bằng GLM-4-Plus là 7 USD, tương đương với mô hình lớn mới nhất của Baidu, Ernie 4.0 Turbo, có giá khoảng 4,2 USD cho đầu vào và 8,4 USD 8,4 cho đầu ra trên một triệu mã thông báo.
Tuy nhiên, điều thực sự mang tính đột phá nằm ở khả năng đa phương thức.
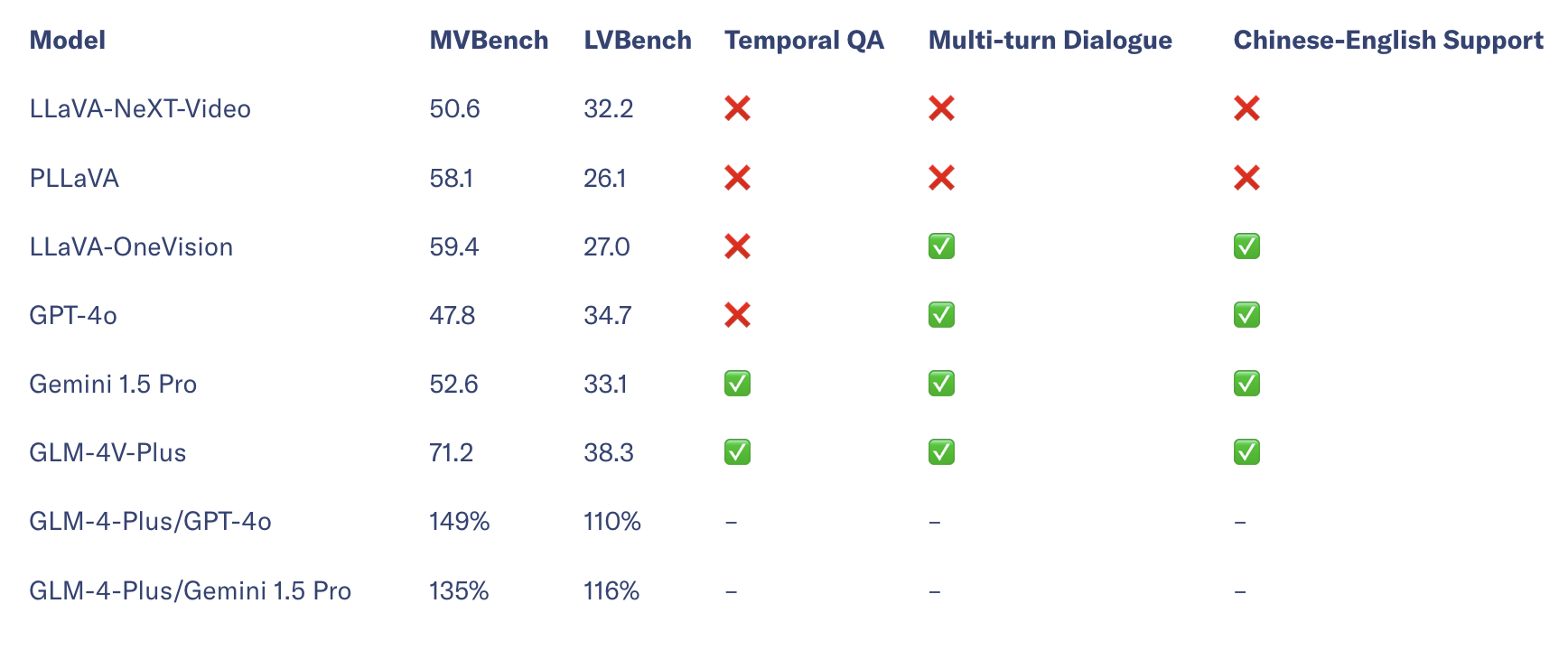
Giờ đây, mô hình trực quan mới GLM-4V-Plus có thể hiểu nội dung video và trang web, đây là cải tiến đáng kể so với phiên bản tiền nhiệm.
Khác với một số mô hình thông thường, GLM-4V-Plus không chỉ hiểu các video phức tạp mà còn ghi nhớ cả thời gian. Người dùng có thể hỏi về khoảnh khắc cụ thể trong video và công cụ sẽ xác định chính xác nội dung. Tuy nhiên, tính đến thời điểm hiện tại, nền tảng mở của Zhipu AI vẫn chưa hỗ trợ tải video lên cho tính năng này.
Mặc dù có khả năng trực quan ấn tượng, GLM-4V-Plus vẫn hụt hơi trong đa số cuộc đối thoại dài và hiểu văn bản, có nghĩa là vẫn chưa ngang bằng GPT-4o ở mặt này.
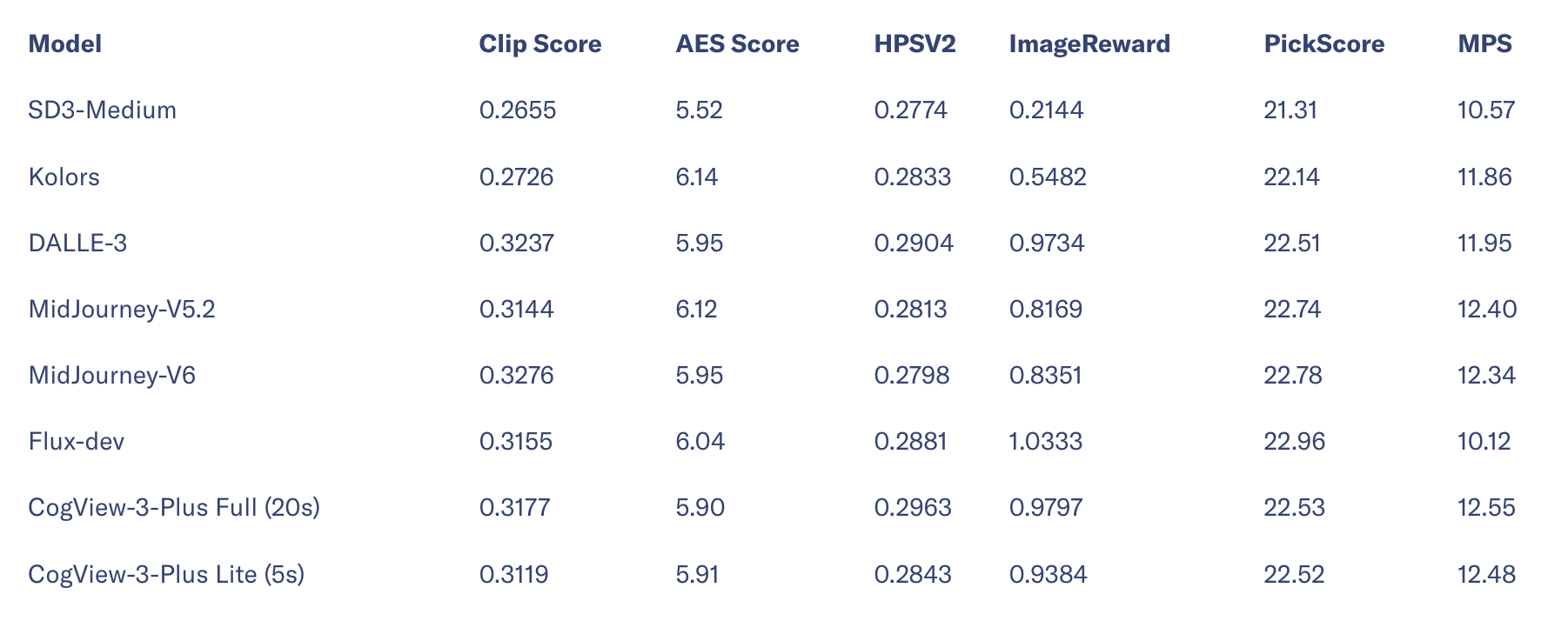
Tại KDD, Zhipu AI cũng giới thiệu CogView-3-Plus, thế hệ tiếp theo của mô hình chuyển văn bản thành hình ảnh. So với FLUX, người tiên phong trong lĩnh vực này, CogView-3-Plus có thể tạo ra hình ảnh trong vòng 20 giây, đồng thời hỗ trợ chỉnh sửa hình ảnh, chẳng hạn như thay đổi màu sắc đối tượng hoặc thay thế các mục trong hình ảnh.
Zhipu AI mất hơn bảy tháng để thêm hậu tố "Plus" vào các mẫu ra mắt từ tháng 1/2024, chu kỳ phát triển dài nhất kể từ năm 2023.
Hầu hết công ty AI của Trung Quốc đang áp dụng chiến lược chia để trị (giải quyết vấn đề lớn bằng cách chia thành nhiều vấn đề nhỏ), trước tiên là tăng cường khả năng đơn phương thức trước khi giải quyết thách thức về tích hợp. Zhipu AI vẫn đang trong giai đoạn này, sự ra mắt tính năng gọi video là thời điểm đầu trong phản ứng tổng hợp đa phương thức.

Thay vì chỉ chạy đua xây dựng những mô hình ngày càng lớn và đắt đỏ, các doanh nghiệp hiện quan tâm nhiều hơn đến các mô hình thông minh và hiệu quả nhất…

Trong khi Apple và OpenAI vướng vào cuộc chiến pháp lý liên quan đến phần cứng AI, startup StepFun của Trung Quốc đã giới thiệu mẫu smartphone được xây dựng hoàn toàn xoay quanh các AI agent, thay vì chỉ bổ sung các tính năng AI lên nền tảng di động truyền thống…

Từ nghiên cứu vật liệu, nông nghiệp, y tế đến chuyển đổi xanh, ngày càng nhiều kết nối giữa các nhà khoa học quốc tế và các nhóm nghiên cứu trong nước đang được chuyển hóa thành những dự án hướng trực tiếp vào các bài toán phát triển của Việt Nam...

Những bước tiến về hiệu quả khai thác, tầm bay và khả năng tiết kiệm nhiên liệu của máy bay thế hệ mới đang làm thay đổi cách ngành hàng không phát triển mạng lưới kết nối trên toàn cầu...

Hội nghị Trí tuệ nhân tạo Thế giới (World Artificial Intelligence Conference - WAIC) 2026 sẽ trở thành sân khấu để Trung Quốc trình làng hàng loạt công nghệ AI thế hệ mới, từ hạ tầng tính toán quy mô lớn đến các thiết bị AI dành cho người dùng cuối…

Dự kiến chi phí linh kiện cho mỗi chiếc xe taxi tự lái sản xuất tại Trung Quốc sẽ giảm xuống còn từ 35.000 đến 40.000 đô la Mỹ vào năm 2027…

Hợp tác giữa Đại sứ quán Đan Mạch và Bảo hiểm Xã hội Việt Nam bước vào giai đoạn hợp tác mới 2026–2028 với trọng tâm là phát triển y tế số, ứng dụng dữ liệu y tế và kinh tế y tế trong hoạch định chính sách…

Trong bối cảnh nền kinh tế số tại Việt Nam phát triển với tốc độ chóng mặt, khối lượng dữ liệu được tạo ra tăng lên vượt bậc, khiến dữ liệu trở thành tài sản giá trị nhưng cũng dễ bị thất thoát và lạm dụng hơn bao giờ hết.

Sau ba năm đứng ngoài bảng xếp hạng TOP500, Trung Quốc đã trở lại đầy ấn tượng khi siêu máy tính LineShine vươn lên vị trí số một thế giới trong bảng xếp hạng tháng 6/2026...

Bộ công cụ có khả năng đánh giá toàn diện năng lực tiếng Việt của các mô hình AI, qua đó cung cấp hệ tham chiếu khách quan, độc lập, làm cơ sở cho việc lựa chọn và ứng dụng AI trong thực tiễn...